ScrapBookを使用してFirefoxでWebサイト全体をダウンロードする
オフラインで表示できるようにWebページまたはWebサイトを保存する必要があります? あなたは長期間オフラインになるでしょうが、あなたのお気に入りのウェブサイトを閲覧できるようにしたいですか? Firefoxを使用している場合は、問題を解決できるFirefoxアドオンが1つあります。.
スクラップブック はあなたがウェブページを保存して管理するのが非常に簡単な方法でそれらを組織するのを助ける素晴らしいFirefox拡張です。このアドオンについての本当に素晴らしいことは、それが非常に軽く、速く、正確にウェブページのローカルコピーをほぼ完全にキャッシュし、そして複数の言語をサポートするということです。私はたくさんのグラフィックと派手なCSSスタイルでいくつかのWebページでそれをテストしました、そしてオフライン版がオンライン版と全く同じに見えたのを見ることが驚くほどうれしかったです.

ScrapBookは次の目的で使用できます。
- 単一のWebページを保存する
- 単一のWebページのスニペットまたは一部を保存する
- Webサイト全体を保存する
- フォルダ、サブフォルダを使用してブックマークと同じ方法でコレクションを整理する
- 全文検索とコレクション全体の高速フィルタリング検索
- 収集したWebページの編集
- Operaのノーツに似たテキスト/ HTML編集機能
ScrapBookをインストールする
この記事の執筆時点で最新バージョンのFirefox(私にとってはv33)を実行している場合は、ScrapBookを正しく使用できるように設定を調整する必要があります。デフォルトでは、ScrapBookアイコンはどこにも表示されないため、Webページを右クリックした場合にのみ使用できます。ツールバーの任意の場所を右クリックしてボタンをツールバーまたはメニューに追加し、 カスタマイズ.

カスタマイズ画面の左側にScrapBookアイコンが表示されます。先に進み、それを一番上のツールバーかメニューのどちらかにドラッグしてください。それから先に行き、をクリックしてください カスタマイズ終了 ボタン.

ScrapBookを使ってWebサイトを保存する前に、アドオンの設定を変更することをお勧めします。右上のメニューボタン(3本の横線)をクリックしてから、 アドオン.

今すぐクリック 拡張機能 をクリックして オプション ScrapBookアドオンの横にあるボタン.

ここでキーボードショートカット、データが保存されている場所、その他の細かい設定を変更できます。.

ScrapBookを使用してサイトをダウンロードする
それでは、実際にプログラムを使用することの詳細に入りましょう。まず、WebページをダウンロードしたいWebサイトをロードします。ダウンロードを開始する最も簡単な方法は、ページ上の任意の場所を右クリックしてどちらかを選択することです。 ページを保存 または ページを別名で保存 メニューの下部に向かって。これら2つのオプションはScrapBookによって追加されました.

ページを保存を使用すると、フォルダを選択してから現在のページのみを自動的に保存できます。他にもオプションが必要な場合は(通常はこれを行います)、[ページを別名で保存]オプションをクリックします。あなたはあなたが選ぶことができる別のダイアログを得るでしょうそしてたくさんのオプションから選ぶでしょう.

重要なセクションは オプション, リンクファイルをダウンロードする セクション 詳細保存 オプションデフォルトでは、ScrapBookは画像やスタイルをダウンロードしますが、Webサイトで適切に機能するためにJavaScriptを追加することができます。.
[リンクされたファイルのダウンロード]セクションではリンクされた画像のみがダウンロードされますが、サウンド、ムービーファイル、アーカイブファイルをダウンロードしたり、ダウンロードするファイルの正確な種類を指定することもできます。特定の種類のファイル(Word文書、PDFなど)へのリンクがたくさんあるWebサイトで、関連するすべてのファイルをすばやくダウンロードしたい場合、これは本当に便利なオプションです。.
最後に、 詳細保存 オプションはあなたがウェブサイトのより大きな部分をダウンロードすることについてどのように行くかということです。デフォルトでは0に設定されています。つまり、サイト上の他のページへのリンクやその他のリンクをたどらないということです。選択すると、現在のページとそのページからリンクされているすべてのものがダウンロードされます。深さ2は、現在のページ、最初のリンク先ページ、および最初のリンク先ページからのリンクからもダウンロードされます。.
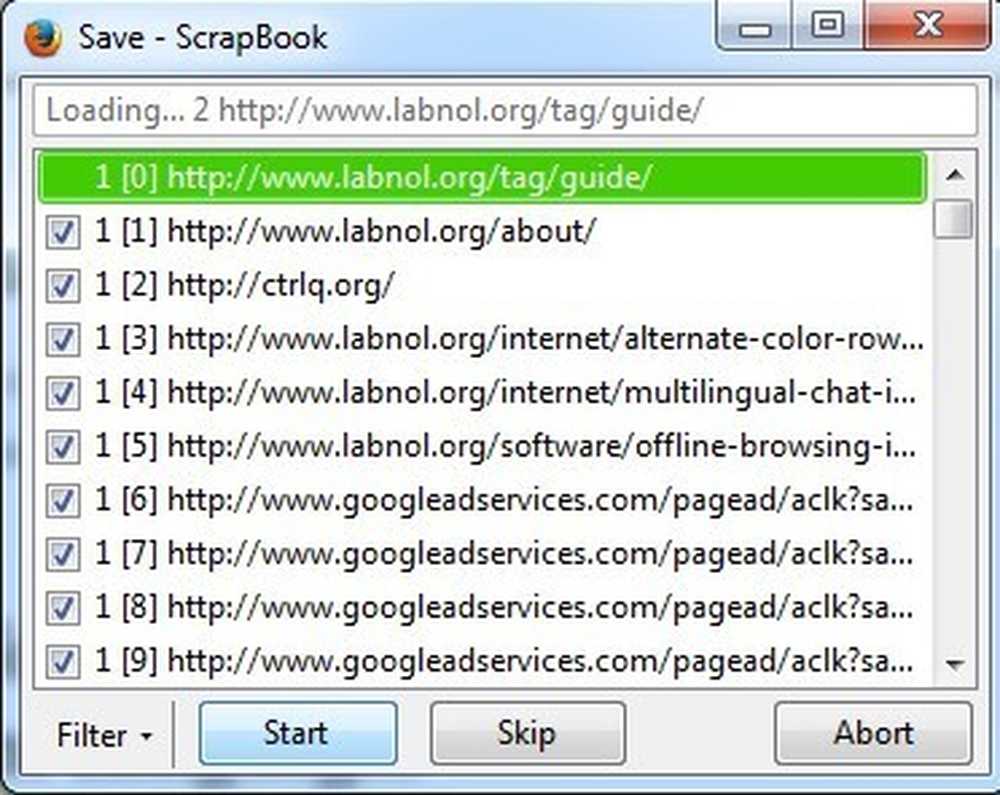
[保存]ボタンをクリックすると、新しいウィンドウがポップアップ表示され、ページのダウンロードが始まります。あなたが押したいと思うでしょう 一時停止 すぐにボタンを押して、その理由を教えてください。 ScrapBookを実行するだけで、他のサイトや広告ネットワークにリンクしている可能性があるソースコード内のすべてのものを含め、ページからすべてのものがダウンロードされます。上の画像からわかるように、メインサイト(labnol.org)の外には、googleadservices.comからの広告とctrlq.orgからの広告がダウンロードされています。.
あなたが本当にそれをオフラインで閲覧している間あなたが広告をそのサイトに現われることを望みますか?これはまた多くの時間と帯域幅を浪費することになるので、行うのが最も良いことはPauseを押してからそれをクリックすることです。 フィルタ ボタン.

最良の2つの選択肢は ドメインに限定 そして ディレクトリに限定. 通常これらは同じですが、特定のサイトでは異なります。どのページが欲しいのか正確にわかっていれば、文字列でフィルタリングして自分のURLを入力することもできます。ソーシャルメディアサイト、広告ネットワークなどからではなく、現在の実際のWebサイトからのみコンテンツをダウンロードするため、このオプションは素晴らしいです。.
進んでクリック 開始 ページがダウンロードされます。ダウンロードする時間はあなたのインターネット接続速度と正確にあなたがダウンロードしているウェブサイト上でどれくらいに依存するでしょう。このアドオンはほとんどのサイトでうまく機能します。私が遭遇した唯一の問題は、一部のサイトでは、自分のコンテンツへのリンクに使用するURLが絶対URLであることです。.
絶対URLの問題は、オフラインのときにFirefoxでインデックスページを開いてリンクのいずれかをクリックしようとすると、ローカルキャッシュからではなく実際のWebサイトからロードしようとすることです。その場合は、ダウンロードディレクトリを手動で開き、ページを開く必要があります。それは痛みであり、私はほんの一握りのサイトでそれが起こっただけでした、しかしそれは起こります。ダウンロードフォルダは、ツールバーのScrapBookボタンをクリックしてからサイトを右クリックして、 道具 - ファイルを表示.

エクスプローラで、並べ替え タイプ それから呼び出されたファイルまでスクロールします。 HTMLドキュメント. コンテンツページは通常、default_00xファイルであり、index_00xファイルではありません。.

Firefoxを使用していなくてもWebページをコンピュータにダウンロードしたい場合は、次のソフトウェアをチェックアウトすることもできます。 WinHTTrackこれにより、後でオフラインで閲覧するためにWebサイト全体が自動的にダウンロードされます。ただし、WinHTTrackはかなりの量のスペースを使い果たすので、ハードドライブに十分な空きスペースがあることを確認してください。.
どちらのプログラムも、Webサイト全体のダウンロードまたは単一のWebページのダウンロードに適しています。実際には、WordPressなどのCMSソフトウェアによって生成される膨大な数のリンクのため、Webサイト全体をダウンロードすることはほとんど不可能です。質問がある場合は、コメントを投稿してください。楽しい!